


- How does one quantify "coherence", i.e. how closely does a formation resemble a rigid lattice? We refer to these as macroscopic performance measures.
- How does one capture the local behavior of vehicles, such as the tendency to run into each other? We refer to these as microscopic performance measures.
- How do these measures scale with formation size, and how do they depend on the network topology and underlying spatial dimension?
- How does all this depend on whether vehicles have local feedback versus global feedback of things like position errors and velocity errors?
The answers to these questions are provided in the paper below. It turns out that a common phenomenon appears where a higher spatial dimension implies a more favorable scaling of coherence measures, with a dimensions of 3 being necessary to achieve coherence in consensus and vehicular formations under certain conditions.
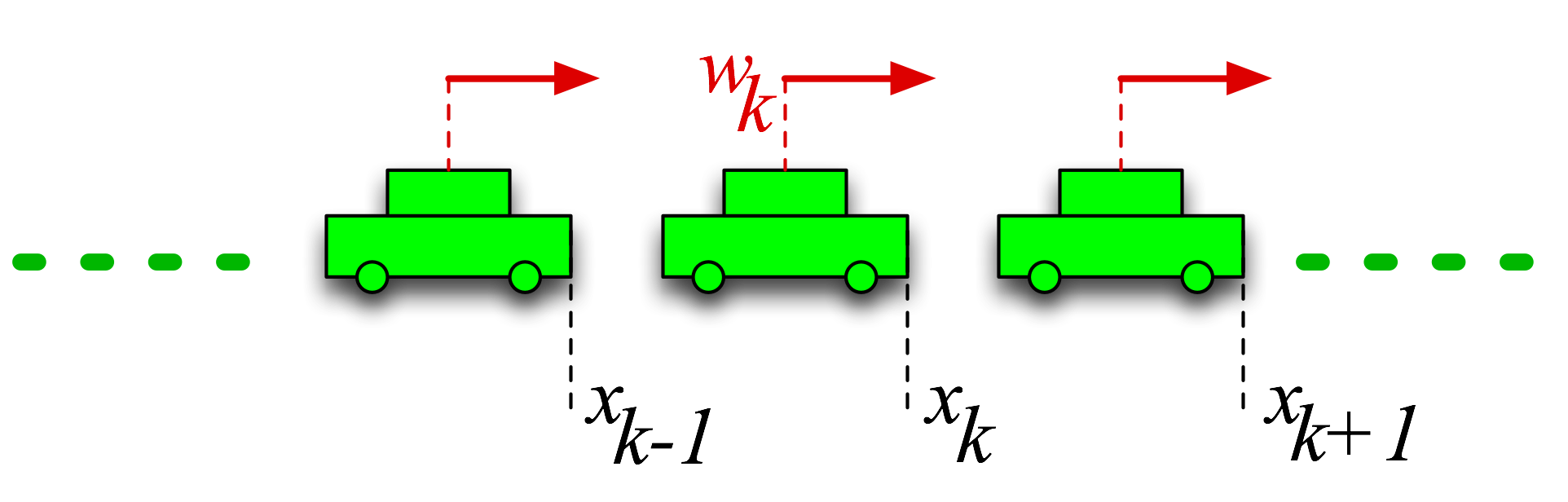
| However, if you simulate the system, here's what you observe. The graph on the right shows the position trajectories of a 100 vehicle formation (relative to leader). It exhibits what can be described as an accordion-like motion in which large shape features in the formation fluctuate. We call this phenomenon a lack of formation coherence. It is only discernible when one "zooms out" to view the entire formation. The length of the formation fluctuates stochastically, but with a distinct slow temporal and long spatial wavelength signature. |

|
| In contrast, the zoomed-in view here shows a relatively well regulated vehicle-to-vehicle spacing. In general, it appears that small scale (both temporally and spatially) disturbances are well regulated, while large scale disturbances are not. An intuitive interpretation of this phenomenon is that local feedback strategies are unable to regulate against large scale disturbances in this one dimensional formation. This is an example of the lack of coherence in this formation. |

|
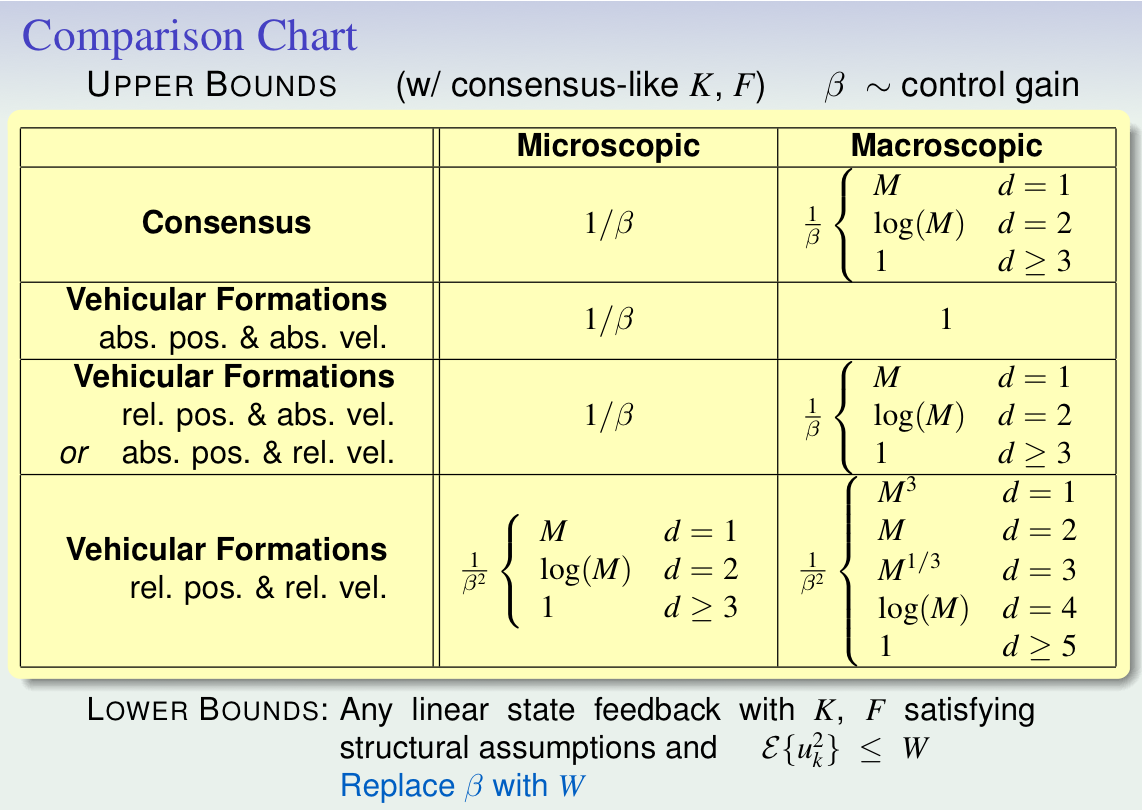
The parameter beta in these tables can be understood as a measure of the control effort at each site.
For all the details, see the preprint:
-
B. Bamieh,
M. Jovanovic,
P. Mitra,
and S. Patterson.
Coherence in Large-Scale Networks: Dimension Dependent Limitations of Local Feedback.
Submitted to IEEE Trans. Aut. Cont.,
2009.
 [bibtex-entry]
[bibtex-entry]