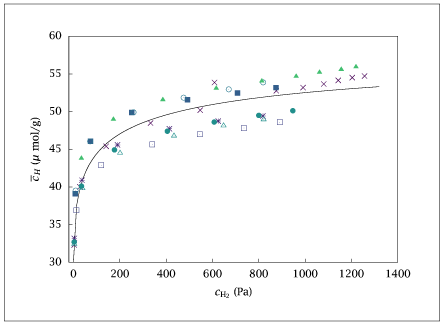
fromparestoimportParestofrommiscimportoctave_saveimportnumpyasnpimportmatplotlib.pyplotaspltimportosplt.ion()# Define the data arraysHgas1=np.array([2.659,27.590,141.038,332.613,546.857,608.583,875.353,991.072,1080.134,1142.782,1203.178,1256.244])Hads1=np.array([32.31,40.02,45.40,48.49,50.19,53.86,52.77,53.19,53.67,54.15,54.51,54.73])Hgas2=np.array([3.755,36.331,189.904,413.881,624.665,817.592])Hads2=np.array([33.17,40.90,45.59,47.72,48.74,49.43])Hgas3=np.array([12.794,119.331,339.917,545.227,735.746,890.642])Hads3=np.array([36.91,42.90,45.65,47.00,47.82,48.60])Hgas4=np.array([7.424,73.312,251.177,491.691,707.806,873.926])Hads4=np.array([39.11,46.06,49.87,51.57,52.48,53.18])Hgas5=np.array([9.176,72.065,259.002,475.250,670.034,818.669])Hads5=np.array([39.52,46.06,49.92,51.86,52.96,53.88])Hgas6=np.array([2.962,34.350,176.860,405.233,607.476,799.723,946.765])Hads6=np.array([32.70,40.11,44.92,47.40,48.62,49.50,50.12])Hgas7=np.array([3.159,38.528,200.877,433.924,647.630,820.673])Hads7=np.array([32.42,39.81,44.51,46.79,48.14,48.95])Hgas8=np.array([34.127,172.316,385.633,616.149,812.932,961.191,1061.967,1155.829,1219.299])Hads8=np.array([43.79,48.97,51.57,53.09,54.05,54.67,55.20,55.60,55.93])# Choose a dataset or datasets to fitcgmeas=np.concatenate([Hgas1,Hgas2,Hgas3,Hgas4,Hgas5,Hgas6,Hgas7,Hgas8])cadsmeas=np.concatenate([Hads1,Hads2,Hads3,Hads4,Hads5,Hads6,Hads7,Hads8])Ks0=2cms0=40cmp0=0defalg_model(t,y,p):return[y.cads-p.cmp-(p.cms*p.sqKs*np.sqrt(y.cgmeas))/(1+p.sqKs*np.sqrt(y.cg)),y.cg-y.cgmeas]deflsq(t,y,p):return[y.cadsmeas-y.cads]# Create an instance of the Paresto class with the modelpe=Paresto()pe.transcription="shooting"pe.nlp_solver_options={'sens_linsol_options':{'eps':0}}pe.z=['cg','cads']pe.p=['sqKs','cms','cmp']pe.d=['cgmeas','cadsmeas']pe.alg=alg_modelpe.lsq=lsqpe.tout=np.arange(1,cgmeas.shape[0]+1)pe.initialize()pe.ic.sqKs=np.sqrt(Ks0)pe.ic.cms=cms0pe.ic.cmp=cmp0pe.ic.cg=100pe.ic.cads=30pe.lb_ub()pe.lb.sqKs=np.sqrt(1e-3)pe.lb.cms=10pe.lb.cmp=0pe.lb.cg=pe.ic.cgpe.lb.cads=pe.ic.cadspe.ub.sqKs=np.sqrt(5)pe.ub.cms=200pe.ub.cmp=100pe.ub.cg=pe.ic.cgpe.ub.cads=pe.ic.cads# Perform optimizationest,yy,pp=pe.optimize(np.vstack([cgmeas,cadsmeas]).reshape(2,len(pe.tout),1))# Calculate confidence intervalsconf=pe.confidence(est,0.95)# Display resultsprint('Estimated parameters')print('\n'.join(f'{k}: {float(v)}'fork,vinest.theta.items()))print('Bounding box intervals')print('\n'.join(f'{k}: {float(v)}'fork,vinconf.bbox.items()))table1=np.column_stack((Hgas1,Hads1))table2=np.column_stack((Hgas2,Hads2))table3=np.column_stack((Hgas3,Hads3))table4=np.column_stack((Hgas4,Hads4))table5=np.column_stack((Hgas5,Hads5))table6=np.column_stack((Hgas6,Hads6))table7=np.column_stack((Hgas7,Hads7))table8=np.column_stack((Hgas8,Hads8))# Set up plotting valuesnplot=100Xplot=np.linspace(0,1.05*np.max(cgmeas),nplot)sqKs=est.theta.sqKscms=est.theta.cmscmp=est.theta.cmpYplot=cms*sqKs*np.sqrt(Xplot)/(1+sqKs*np.sqrt(Xplot))+cmp# Combine plot datatable_all=np.column_stack((Xplot,Yplot))octave_save('adsall.dat',('table_all',table_all),('table1',table1),('table2',table2),('table3',table3),('table4',table4),('table5',table5),('table6',table6),('table7',table7),('table8',table8),)# Check the environment variable for plottingifnotos.getenv('OMIT_PLOTS')=='true':plt.figure()plt.plot(table_all[:,0],table_all[:,1],label='Model Fit')plt.plot(table1[:,0],table1[:,1],'+',label='Table 1')plt.plot(table2[:,0],table2[:,1],'x',label='Table 2')plt.plot(table3[:,0],table3[:,1],'*',label='Table 3')plt.plot(table4[:,0],table4[:,1],'o',label='Table 4')plt.plot(table5[:,0],table5[:,1],'+',label='Table 5')plt.plot(table6[:,0],table6[:,1],'x',label='Table 6')plt.plot(table7[:,0],table7[:,1],'*',label='Table 7')plt.plot(table8[:,0],table8[:,1],'o',label='Table 8')plt.legend()ifnotos.getenv('OMIT_PLOTS')=='true':plt.show()