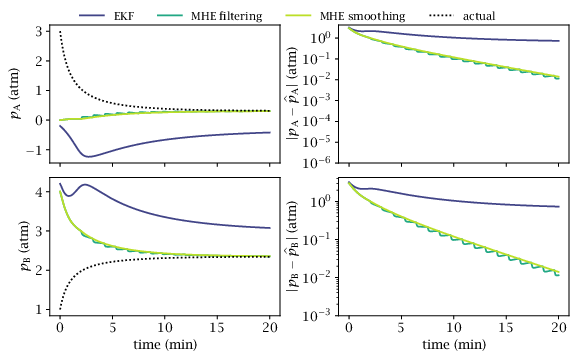
# [makes] priorupdates.mat## Comparison of different prior update strategies for a nonlinear system.# Also compares EKF.importsysimportossys.path.insert(0,os.path.join(os.path.dirname(os.path.abspath(__file__)),'functions'))importnumpyasnpimportcasadiimportmpctoolsasmpcimportscipy.ioassioNx=2Ny=1Nt=10# MHE horizonk1=0.16k2=0.0064Delta=0.1defode(x):returnnp.array([-2*k1*x[0]**2+2*k2*x[1],k1*x[0]**2-k2*x[1]])defmeasurement(x):returnx[0]+x[1]sim=mpc.getCasadiIntegrator(ode,Delta,[Nx],['x'],funcname='sim',verbosity=0)f=mpc.getCasadiFunc(ode,[Nx],['x'],funcname='f',rk4=True,Delta=Delta)h=mpc.getCasadiFunc(measurement,[Nx],['x'],funcname='h')# Simulate system (no noise).Nsim=200xsim=np.full((Nx,Nsim+1),np.nan)xsim[:,0]=[3.0,1.0]ysim=np.full((Ny,Nsim+1),np.nan)foriinrange(Nsim+1):ysim[:,i]=[measurement(xsim[:,i])]ifi<Nsim:xsim[:,i+1]=np.array(sim(xsim[:,i])).flatten()t=np.arange(Nsim+1)*Delta# MHE costs.Q=np.diag([1e-4,1e-2])R=np.diag([1e-2])P0=np.diag([1.0,1.0])Qinv=np.linalg.inv(Q)Rinv=np.linalg.inv(R)P0inv=np.linalg.inv(P0)w_sym=casadi.SX.sym('w',Nx)v_sym=casadi.SX.sym('v',Ny)l=casadi.Function('l',[w_sym,v_sym],[casadi.mtimes(w_sym.T,casadi.mtimes(Qinv,w_sym))+casadi.mtimes(v_sym.T,casadi.mtimes(Rinv,v_sym))],['w','v'],['l'])x0bar_init=np.array([0.1,4.5])N={'x':Nx,'y':Ny,'t':Nt}lb={'x':np.zeros(Nx)}xs={'actual':xsim}ys={'actual':ysim}# Growing-horizon startup: at step i the MHE has horizon i with measurements# y(0)..y(i). At i=Nt the window first fills and the persistent full-horizon# solver takes over. Filtering and smoothing solve identical NLPs while the# window is filling, so they agree exactly through k=Nt; they diverge once# newmeasurement begins shifting the window and the prior update fires.defmake_solver(N_t,y_window,priorupdate):Nd={'x':Nx,'y':Ny,'t':N_t}returnmpc.nmhe(f,h,np.zeros((N_t,0)),y_window,l,Nd,lb=lb,par={'x0bar':x0bar_init.copy(),'Pinv':P0inv.copy().flatten()},funcargs={'f':['x'],'h':['x'],'l':['w','v']},wAdditive=True,verbosity=0,priorupdate=priorupdate)forupdate_typein['filtering','smoothing']:print('Simulating MHE with %s update.'%update_type)xmhe=np.full((Nx,Nsim+1),np.nan)ymhe=np.full((Ny,Nsim+1),np.nan)full_solver=Noneforiinrange(Nsim+1):ifi<Nt:# Growing-horizon startup: horizon i, measurements y(0)..y(i).# Pass priorupdate=update_type so lx (arrival cost) is auto-built# from par['x0bar'] and par['Pinv']; saveestimate is never called# on these short-window solvers, so the prior-update logic itself# is inert and filtering/smoothing solve identical NLPs here.y_win=ysim[:,:i+1].Tsolver=make_solver(i,y_win,priorupdate=update_type)solver.solve()ifsolver.stats['status']!='Solve_Succeeded':print('Warning: startup solver failure at step %d!'%i)breakxmhe[:,i]=np.array(solver.var['x',i]).flatten()else:# Window full: build the persistent full-horizon solver once,# then advance with newmeasurement.iffull_solverisNone:y_win=ysim[:,i-Nt:i+1].T# y(0..Nt) when i == Ntfull_solver=make_solver(Nt,y_win,priorupdate=update_type)else:full_solver.newmeasurement(ysim[:,i])full_solver.solve()iffull_solver.stats['status']!='Solve_Succeeded':print('Warning: solver failure at time %d!'%i)breakfull_solver.saveestimate()xmhe[:,i]=np.array(full_solver.var['x',Nt]).flatten()ymhe[:,i]=[measurement(xmhe[:,i])]xs[update_type]=xmheys[update_type]=ymhe# EKF (G = I: process noise enters all states).print('Simulating EKF.')Afunc=f.factory('Afunc',f.name_in(),['jac:f:x'])Cfunc=h.factory('Cfunc',h.name_in(),['jac:h:x'])xekf=np.full((Nx,Nsim+1),np.nan)xekf[:,0]=x0bar_init.copy()P=P0.copy()yekf=np.full((Ny,Nsim+1),np.nan)foriinrange(Nsim+1):e=ysim[:,i]-np.array(h(xekf[:,i])).flatten()C=np.array(Cfunc(xekf[:,i])).reshape(Ny,Nx)L=P@C.T@np.linalg.inv(C@P@C.T+R)P=P-L@C@Pxekf[:,i]=xekf[:,i]+L@eyekf[:,i]=[measurement(xekf[:,i])]ifi<Nsim:A=np.array(Afunc(xekf[:,i])).reshape(Nx,Nx)xekf[:,i+1]=np.array(f(xekf[:,i])).flatten()P=A@P@A.T+Qxs['ekf']=xekfys['ekf']=yekfsio.savemat('priorupdates.mat',{'x':xs,'y':ys,'t':t})