# [ustar, uiter] = distributedgradient(V, u0, ulb, uub, ...)## Runs a distributed gradient algorithm for a problem with box constraints.## V should be a function handle defining the objective function. u0 should be# the starting point. ulb and uub should give the box constraints for u.## Additional arguments are passed as 'key' value pairs. They are as follows:## - 'beta', 'sigma' : parameters for line search (default 0.8 and 0.01)# - 'alphamax' : maximum step to take in any iteration (default 10)# - 'Niter' : Maximum number of iterations (default 25)# - 'steptol', 'gradtol' : Absolute tolerances on stepsize and gradient.# Algorithm terminates if the stepsize is less than# steptol and the gradient is less than gradtol# (defaults 1e-5 and 1e-6). Set either to a negative# value to never stop early.# - 'Nlinesearch' : maximum number of backtracking steps (default 100)# - 'I' : cell array defining the variables for each system. Default is# each variable is a separate system.## Return values are ustar, the final point, and uiter, a matrix of iteration# progress.importnumpyasnpfromcasadiimportSX,jacobian,Functiondefdistributedgradient(V,u0,ulb,uub,**kwargs):""" Runs a distributed gradient algorithm for a problem with box constraints. """# Get optionsparam={'beta':0.8,'sigma':0.01,'alphamax':15,'Niter':50,'steptol':1e-5,'gradtol':1e-6,'Nlinesearch':100,'I':None}param.update(kwargs)Nu=len(u0)ifparam['I']isNone:param['I']=[[i]foriinrange(Nu)]# Project initial condition to feasible spaceu0=np.minimum(np.maximum(u0,ulb),uub)# Get gradient function via CasADiusym=SX.sym('u',Nu)vsym=V(usym)Jsym=jacobian(vsym,usym)dVcasadi=Function('V',[usym],[Jsym])# Start the loopk=0uiter=np.full((Nu,param['Niter']+1),np.nan)uiter[:,0]=u0g,gred=calcgrad(dVcasadi,u0,ulb,uub)v=np.full(Nu,np.inf)whilek<param['Niter']and(np.linalg.norm(gred)>param['gradtol']ornp.linalg.norm(v)>param['steptol']):# Take stepuiter[:,k+1],v=coopstep(param['I'],V,g,uiter[:,k],ulb,uub,param)k+=1# Update gradientg,gred=calcgrad(dVcasadi,uiter[:,k],ulb,uub)# Get final point and strip off extra pointsuiter=uiter[:,:k+1]ustar=uiter[:,-1]returnustar,uiterdefcoopstep(I,V,g,u0,ulb,uub,param):""" Takes one step of cooperative distributed gradient projection. """Nu=len(u0)Ni=len(I)us=np.full((Nu,Ni),np.nan)Vs=np.full(Ni,np.nan)# Run each optimizationV0=float(V(u0))forjinrange(Ni):# Compute stepv=np.zeros(Nu)i=I[j]v[i]=-g[i]ubar=np.minimum(np.maximum(u0+v,ulb),uub)v=ubar-u0# Choose alphaifnp.any(ubar==ulb)ornp.any(ubar==uub):alpha=1.0else:withnp.errstate(divide='ignore'):alpha_lb=(ulb[i]-u0[i])/v[i]alpha_ub=(uub[i]-u0[i])/v[i]alpha=np.concatenate([alpha_lb,alpha_ub])alpha=alpha[np.isfinite(alpha)&(alpha>=0)]iflen(alpha)==0:alpha=0.0else:alpha=min(np.min(alpha),param['alphamax'])# Backtracking line searchk=1whilefloat(V(u0+alpha*v))>V0+param['sigma']*alpha*np.dot(g[i].flatten(),v[i].flatten()) \
andk<=param['Nlinesearch']:alpha=param['beta']*alphak+=1us[:,j]=u0+alpha*vVs[j]=float(V(us[:,j]))# Choose step to takew=np.ones(Ni)/Niforjinrange(Ni):# Check for descentu=us@wiffloat(V(u))<=np.dot(Vs,w):breakelifj==Ni-1:u=u0.copy()print('Warning: No descent directions!')break# Get rid of worst playerjmax=np.argmax(Vs)Vs[jmax]=-np.finfo(float).maxw[jmax]=0w=w/np.sum(w)# Calculate actual stepv=u-u0returnu,vdefcalcgrad(dV,u,ulb,uub):""" Calculates gradient and reduced gradient at a given point. """g=np.array(dV(u)).flatten()gred=g.copy()gred[(u==ulb)&(g>0)]=0gred[(u==uub)&(g<0)]=0returng,gred
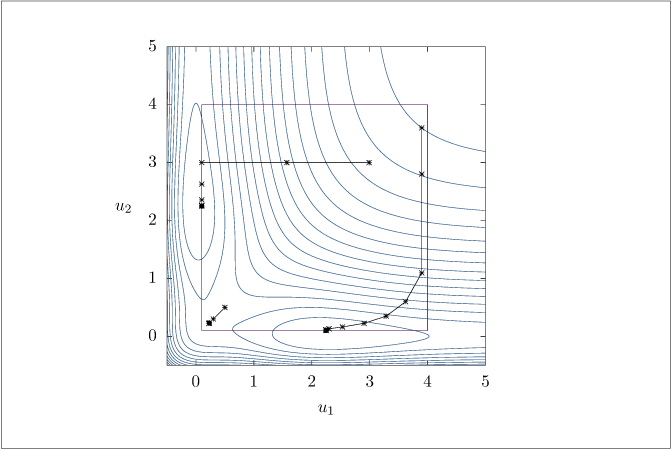
# Example of nonconvex optmization using cooperative optimization.# [depends] functions/distributedgradient.pyimportsysimportosimportmatplotlib.pyplotaspltimportnumpyasnpimportcasadiascasys.path.append('functions/')fromdistributedgradientimportdistributedgradientfromstackcontoursimportstackcontoursfrommiscimportgnuplotsavenxy=221xvec=np.linspace(-0.5,5,nxy)yvec=np.linspace(-0.5,5,nxy)ncont=15defV_numpy(x,y):a=1.1b=0.4return(np.exp(-2*x)-2*np.exp(-x)+np.exp(-2*y)-2*np.exp(-y)+a*np.exp(-b*((x+0.2)**2+(y+0.2)**2)))defVfunc(u):x,y=u[0],u[1]a=1.1b=0.4return(ca.exp(-2*x)-2*ca.exp(-x)+ca.exp(-2*y)-2*ca.exp(-y)+a*ca.exp(-b*((x+0.2)**2+(y+0.2)**2)))xgrid,ygrid=np.meshgrid(xvec,yvec)Vgrid=V_numpy(xgrid,ygrid)# Run distributed optimization for different initial conditions.ulb=0.1*np.ones(2)uub=4.0*np.ones(2)U=np.array([[uub[0],ulb[0],ulb[0],uub[0],uub[0]],[uub[1],uub[1],ulb[0],ulb[0],uub[1]]])Nu=2u0s=np.array([[0.5,0.5],[3.9,3.6],[2.99,3.0]]).TNu0=u0s.shape[1]uiter=[None]*Nu0foriinrange(Nu0):_,uiter[i]=distributedgradient(Vfunc,u0s[:,i],ulb,uub)# Make a plot.ifnotos.getenv('OMIT_PLOTS')=='true':plt.figure()cs=plt.contour(xvec,yvec,Vgrid,ncont)ifnotos.getenv('OMIT_PLOTS')=='true':plt.plot(U[0,:],U[1,:],'-k')markers='os^<>v'foriinrange(Nu0):plt.plot(uiter[i][0,:],uiter[i][1,:],f'-{markers[i]}k')